非線形回帰チュートリアル
弊社ユーザーページ で紹介している「非線形回帰チュートリアル」より一部抜粋して紹介しています。「非線形回帰チュートリアル」では、日本語アドオンの画像が使用されておりますが、当該チュートリアルでは英語版(Mac版)を使用しております。
非線形回帰とは
よくある誤解
- データを入力すれば自動的にシグモイド曲線を生成し、IC/EC50値を算出してくれる?
- いいえ。正しいモデルに正しいデータを入力して初めて算出できます。いずれかが間違っていれば、それは価値のない間違った値です。
- どんなデータでもフィットできる?
- いいえ。できません。
- データの単位や形式を気にする必要はない?
- いいえ。あります。
- 最適合値が出力されたモデル式が、そのデータの反応式?
- いいえ。解析者が妥当なモデル式を選択して最適合値を算出します。解釈が逆です。
- モデル式の選択を気にする必要はない?
- いいえ。常に気にする必要があります。
- フィットのモデル式は自動的に生成される?
- いいえ。自動的には生成されません。自動生成させる仕組みを作ることはできますが、選ばれたモデル式の妥当性は解析者が判断することです。GraphPad Prismでは、モデルの自動生成は採用していません。
- 最適合値として出力された値の信頼性はどれも同じ?
- いいえ。正しいモデル式のもとで計算した場合の最適合値であっても、信頼区間の広さで信頼性は変わります。
- Excelのグラフ機能で線を滑らかにすればモデルフィッティングになる?
- いいえ。それは、たいていの場合、単にスムージング(平滑化)してデータを見やすくしただけです。モデルについてはこだわりがなく、考察できるような最適合値が必要ないならば、これで事足りる場合もあります。つまり、解析者の目的によります。
本資料ではこれらのことも交えながら、非線形回帰について説明していきます。
なぜ非線形回帰分析を使うのか
研究者が示したい反応メカニズム(モデル)が、多くの場合本質的に非線形だからです。
反応のメカニズムはモデルで表現され、モデルの項(パラメータ)が積の関係にある場合、非線形の関係にあることに相当します。 実験により得られたデータをモデルにあてはめて、誤差が最小になるように、最適な解(パラメータ推定値)を得ることが回帰分析です。これは線形、非線形とも同じ理論に基づいています。線形式は解析的に解けますが、非線形式の場合は数値的に解く必要があることだけが異なります。分析を行う研究者は、この違いの本質について詳しく知る必要はありません。
GraphPad Prism を使えば医薬品研究、臨床研究で用いるモデルの多くがビルトインされており、線形回帰と非線形回帰のどちらを使うかで迷う必要は全くありません。
パーソナルコンピューター(PC)が広く普及していなかった時代(およそ1995年以前)は、例えば50%効果量を示す場合、最小反応を0、最大反応を100に基準化し、直線的に反応する濃度範囲で直線回帰を行うことが一般的に行われていました。なぜならば、非線形式を数値的に解く手間が膨大であり、実験の合間にできるような作業量ではなかったからです。しかし、PCが高度に発達した現代では非線形式をダイレクトに算出することが当たり前で、計算は瞬時に終わります。線形モデルに近似して最適解を求める方がずっと手間がかかるだけでなく、推定精度が非線形に比べて劣るため、線形モデルを選ぶ必要はありません。
どのようなときに使うのか
非線形回帰が使われるのは、以下のような場合です。
- 薬物の反応メカニズムを証明するとき
- 薬物の反応(効力・効果量:potency、最大反応効果:efficacyなど)を定量的に示すとき
- 反応の最大Maxや、50%阻害濃度IC50、酵素阻害定数Ki、反応のレンジ(濃度幅)を表すHill係数などを求めるとき
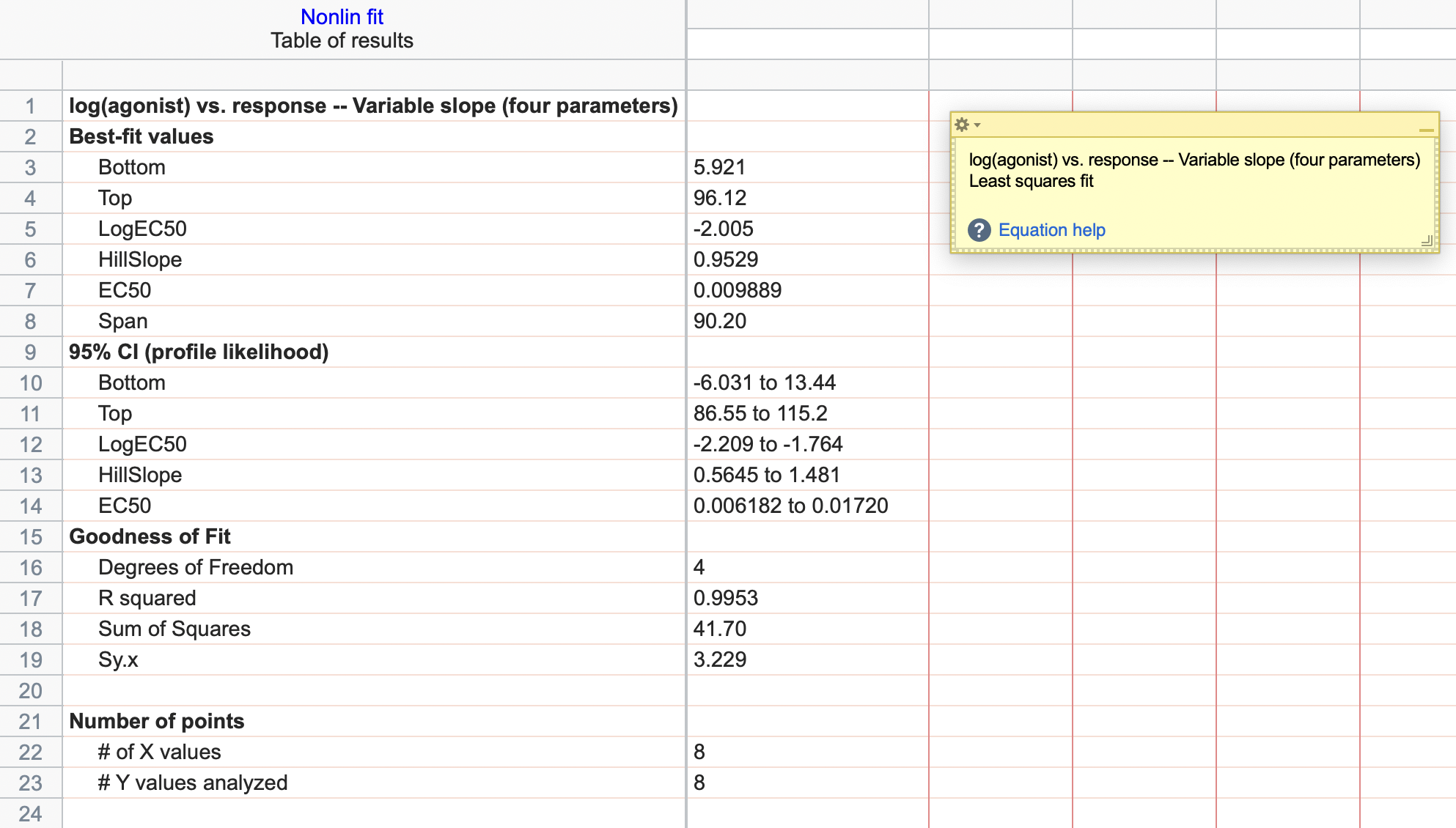
GraphPad Prism で得られたこれらの係数は最適合値(Best-fit value)として出力されます。一般にはパラメータ推定値(Parameter estimate)と呼ばれており、これらは同一のものです。
信頼区間の重要性
GraphPad Prism では、最適合値の推定精度を表す信頼区間も同時に推定します。
メカニズムの証明の際、最適合値の推定精度の情報は重要です。科学論文に原稿を提出する場合、規制当局に結果を報告する場合のほとんどにおいて最適合値の推定精度を表す指標として標準誤差あるいは信頼区間(実験を繰り返したときに、その範囲に入る確率)を併記するよう求められます。最適合値は信頼区間と共に示すようにしてください。データを取得した研究者(あるいはその研究者が所属する組織の長)が信頼区間を不要だと思っていても、結果を評価する立場の第三者(QA担当者、査察官、査読者)は最適合値だけで納得する場合は稀です。なぜならば、推定精度が示されない推定値にどの程度の信頼性があるのか、分からないからです。
新たなメカニズムの薬物等の薬物特性等を論文投稿した際、最適合値の信頼区間がないために、査読者からリバイス指示を出されるケースは多いです。リバイスに応じない場合、論文はリジェクトされることがあるため、最初から論文中に最適合値とともに信頼区間を示すことをお勧めします。 ただし、既にメカニズムが分かっている複数の薬物の薬効プロファイリング試験等ではIC50のみのパネル表示や、データとシグモイドカーブ表示が適している場合もあります。どの推定値をどのように示したらよいかについては、その科学(医学、薬理学等)に精通した研究者の判断とセンスにより決定することであり、統計学的側面から決められるものではありません。
得られたデータを見やすくするためにデータをつなぐ線をスムージングしたい場合があるかもしれません。スムージングに使われる関数は統計学的に線形の場合(多項式)、非線形(スプライン関数等)の場合の両方があります。GraphPad Prismはこれらのフィッティング機能を搭載しています。ただし、気を付けたいのは、スムージングはいわゆる回帰分析=何か特定のメカニズムを想定したモデル解析とは別のものです。Excelのグラフ機能で滑らかな曲線を描く機能や分析ツールの移動平均の機能もそれにあたります。
非線形回帰で何が分かるのか
薬理メカニズムに従った反応であるかが示唆でき、そのメカニズムに基づいた最適合値(EC50、Ki、Kmなど)とその推定精度(信頼区間)が計算できます。
想定した薬理メカニズムに従った反応であれば、モデルにフィット=妥当な最適合値が計算されるはずです。モデルにフィットしない場合は、何らかの想定外の事象を介した反応、すなわちアーティファクトを捉えている可能性があります。
線形回帰が有用な場合
線形回帰が有用なのは以下の場合です。
- 酵素阻害剤の阻害様式を検討するとき
- 実験に利用できる基質量や薬物量が限られており、直線領域でしか検討できないとき
- 薬物の作用メカニズムを含めた検討が不要なとき(スクリーニング)
阻害剤の濃度、基質の濃度を変えて、実験を行い、逆数変換した値を線形にフィットさせ、その形状から阻害様式を検討します。 理論的に実験誤差が歪むことが知られており、回帰の推定精度が極端に低下することが知られています。そのため、推定値を算出する際に逆数変換した値と線形モデルを用いて最適合値を計算すべきではありません。
近年、評価系の感度の向上、ロボット技術の向上により、小サンプルで高速な実験(ハイスループットスクリーニング)が可能になってきました。この場合、十分なデータポイントを検討できるため、線形回帰をあえて使う必要はありません
非線形回帰は線形回帰と何が違うのか
線形、非線形ともに同じ理論(最小二乗法)に基づいて最適合値を求めます。線形式は解析的に解けますが、非線形式の場合は数値的に解く必要があることだけが違います。また、ソフトウェア内部では、どちらも数値的に解いています。GraphPad Prismが採用しているアルゴリズムの詳細は GraphPad Software 社のオンラインガイド Comparing linear regression to nonlinear regression または フィッティングガイド*( 第3章カーブフィッテイングの原理 > 3.単回帰の原理:線形回帰と非線形回帰の比較)を参照ください。
線形回帰ではEC50を示すことはできても、反応の最大や傾き(反応する濃度幅)を定量化することはできません。 逆数変換等を行って線形回帰で推定すると、分散が歪み、信頼性に乏しいことが理論的に知られています。フィッティングしにくいデータを線形変換し、線形回帰を行うと、最適合値にバイアスが入ることも懸念されます。
日本語アドオンをご利用の方は、 回帰の原理 > 単回帰の原理 > 線形回帰と非線形回帰の比較 からもご覧頂けます。
非線形回帰分析を行うために必要なこと
用量反応関係を調べるために、ある薬物の活性を評価する場合を例にとってみましょう。
正しいデータを取得すること
- 評価系の最適化
- 非線形分析に限ったことではありませんが、実験の評価系が安定していることが重要です。結果に再現性が得られるかどうか、プレート(試験管)間の測定誤差が一定しているかどうか等について、事前に確認しておく必要があります。再現性が得られない結果は信頼性がないので、新たな薬物評価を進めるべきではありません。コントロールとなる薬物で評価系を最適化することが先決です。
- 実験の繰り返し(再現性)
- 実験の再現性はとても重要で、通常3回以上の繰り返し実験を行って結果を評価する必要があります。
正しいモデルを選択すること
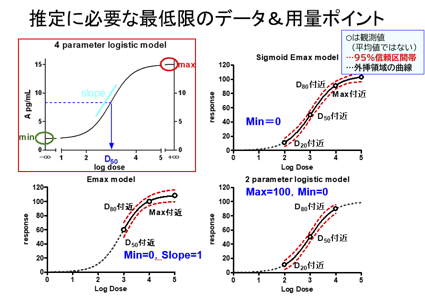
用量反応関係の解析では、4パラメータロジスティックモデルがよく用いられます。
推定するパラメータは4つ(反応の最大(Max)、最小(Min)、50%効果量(EC50)、ヒル係数(Slope)になります。この場合、必要なデータポイントは最低5ポイント(推定すべきパラメータ数+1)になります。EC50を推定する場合、想定されるEC50の濃度を挟み、両側ともに2ポイントが必要になると考えられます。なお、MaxとMinも推定すべきパラメータなので最大付近(おおむね90%)と最小付近(おおむね10%)のデータも取得できるように6-7ポイント程度の濃度を設定した実験デザインを組む必要があります。
精製した受容体(標的)とリガンド(薬物)の実験であり、1対1の結合であれば、理論的にSlopeは1になります。
こういった実験の場合はSlopeを1に固定し、推定すべきパラメータを減らすことができます。 一方、標的が細胞内にあり、細胞外に薬物を添加するような実験系の場合、細胞膜を経由して、トランスポーターや共輸送タンパクなど、別の分子を介して間接的に標的に作用するような薬物の場合、ある閾用量を境に急峻に反応が起こる反応もあれば、逆に緩徐な場合もあります。このような場合、最初からSlopeを1に固定することは妥当ではありません。
評価すべき薬物の数に対して実験材料が十分に取得できない場合で、薬物のEC50に興味がある場合、最大値100、最小値0になるようにデータを基準化したうえで、パラメータを Max と Min を100と0に固定し、EC50を効率よく推定することも考慮できます。ただしこの場合は、データを基準化したため、薬物の Max つまり最大効果は推定できないことになります。実験の目的に応じて適用するモデルを考えることが重要です。常に正しいモデルというものは存在しません。
必ずフィットできるわけではありません
推定すべきモデルのパラメータ数よりも少ないデータポイント数でしか実験していなければ、最適合値は計算できません。GraphPad Prism では、データポイントより少ないデータを入力した場合、結果のテーブルに「ポイントが少なすぎます」"Too few points"と表示されます。
必要なデータポイントは推定すべきパラメータ数+1以上です。この条件に加え、推定すべきパラメータ付近にデータポイントを設定する必要があります。たとえば、Max付近の反応がプラトー(上側の反応カーブがS字になっていない場合は、Maxは推定できないか、95%信頼区間が非常に広くなり、推定の信頼性がない値となります。以下に、代表的な用量反応モデルにて、推定に必要な最低限のデータ数とデータポイントの関係を示します。
パラメータの一部を固定値とすることや(先の例のようにHill係数を1とすることや、反応を基準化してminを0、maxを100とするなど)複数のモデルで共有することで、パラメータ数を削減することで算出できる場合があります。ただし、これらは本来、本格的な実験を行う前の予備実験で条件検討しておくことです。
詳細は GraphPad Software 社のオンラインガイド Analysis checklist: Fitting a model または フィッティングガイド*( 第4章Prism による回帰 > 5.Prism の非線形回帰:非線形回帰の結果の解釈)に非線形回帰分析のチェックリストがあるので参照してください。
日本語アドオンをご利用の方は、 Prism による回帰 > Prism の非線形回帰 > 非線形回帰の結果の解釈 > 分析チェックリスト:非線形回帰 からもご覧頂けます。
結果を正しく解釈すること
薬物AのEC50の最適合値が 10 nM、その95%信頼区間が 1~100 nM、薬物Bの最適合値が 30 nM、その95%信頼区間が 10~100 nMだったとしましょう。この結果から薬物Aは薬物Bよりも3倍強い活性をもつと結論付けて良いでしょうか。
両剤の95%信頼区間はかぶっており、この結果から3倍強いと結論付けることはできません。薬物Aの95%信頼区間はとても広い値を示していますので、そもそもモデルへの当てはまりが悪いと言えるかもしれません。そして、その原因が何に基づいているのか、グラフを見ながら、よく検討することが必要です。反応が頭打ちになり、高用量で反応性が落ちていることがあるかもしれません。
行ってはいけないこと
研究には調べたい仮説があり、研究者は何らかの仮説を立てて実験を行います。仮説と異なる結果が出た場合、実験に誤りがあるのか、立てた仮説が間違っているのか、一旦立ち止まってよく考える必要があります。仮説が支持されなかったからといって、仮説に合うような解析をむやみに探して、無理やりその解析を行うべきではありません。
新たな仮説が生まれ、その結果、イノベーションが生まれることがあります。 本稿では、In vitroの薬物評価法の詳細は述べませんが、出るはずの結果が出なかった場合、統計側の問題なのか、そもそも薬理学やアッセイ方法(固有技術)の問題なのか、よく考えてみましょう。
参考文献
Assay Guidance Manual
https://www.ncbi.nlm.nih.gov/books/NBK53196/
Tonge PJ.Quantifying the Interactions between Biomolecules: Guidelines for Assay Design and Data Analysis. ACS Infect Dis. 2019 Jun 14; 5(6): 796–808.
酵素阻害剤の評価方法
Robert A. Copeland. Evaluation of Enzyme Inhibitors in Drug Discovery: A Guide for Medicinal Chemists and Pharmacologists, 2nd Edition
GraphPad Prismでの非線形回帰の留意点
プロファイル尤度法による信頼区間の算出
信頼区間がプロファイル尤度法(正確な方法)で算出されます。詳細はヘルプから確認できます。しかし、統計学の研究者を除けば、導出法の詳細を理解する必要はありません。
GraphPad Prism7 以前は近似法(Wald法)で算出されていました。データが少ないとき(主にデータポイントが少なくかつモデルへの当てはまりが良くない場合)、プロファイル尤度法での信頼区間が計算できない場合があります。 その際は、近似法を使うことも可能です。現在でも近似法は多く用いられます。ただし、データを取得してから手法を切り替えるのは望ましいことではありません。本番のデータを取得する前に、条件検討しておくことが望ましいです。また、GraphPad Prism7 以前から、同じ薬物を近似法で計算している場合は、整合性をとるために、どちらかに統一しておいた方がよいでしょう。
近似法の使用方法
Confidence タブを開き、Confidence intervals (CI) of parameters の項目にある 1 Symmetrical (asymptotic) approximate CI を選びます。
今後の解析で方法を統一する場合は、2 Make these choices the default for future fits にチェックを入れます。
このように、プロファイル尤度法と近似法のどちらでも解析することができるのは、日本語に対応しているGUIベースのアプリケーションはGraphPad Prismだけです。
実数モデル、対数モデルの両方がある
GraphPad Prism にはX(用量)が実数のモデルと対数のモデルの両方がビルトインモデルとして実装されています。
対数モデルを選択した場合は、Xはlog値をとった値にする必要があります。もし、実数のまま解析を実施すると、グラフは描けているのに、あいまいなフィットになり、最適合値は実際とはかけ離れた値になります。不適切なモデルを選んだ場合、必ずしもPrism はエラーを返さないことに注意してください。
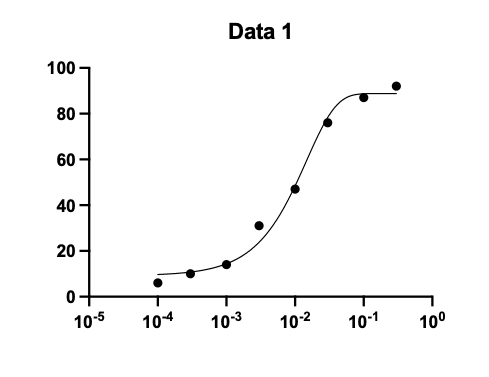
対数用量モデルの場合は、薬物の用量は対数値で与える必要があります。誤って実数用量で与えた場合でも、Prism でグラフ化する際、あたかもS字曲線が描画されることがあります。
Xは実数なのに対数モデルを選んで出力されたグラフ
Xが対数で対数モデルを選んで出力されたグラフ
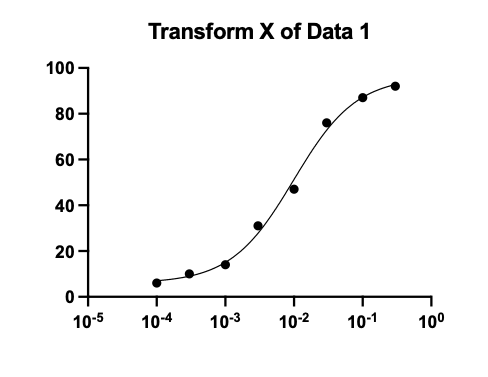
しかし、結果をみると、最適合値がデータとかけ離れたおかしな値となっており、95%信頼区間が異常に広い範囲をとります。
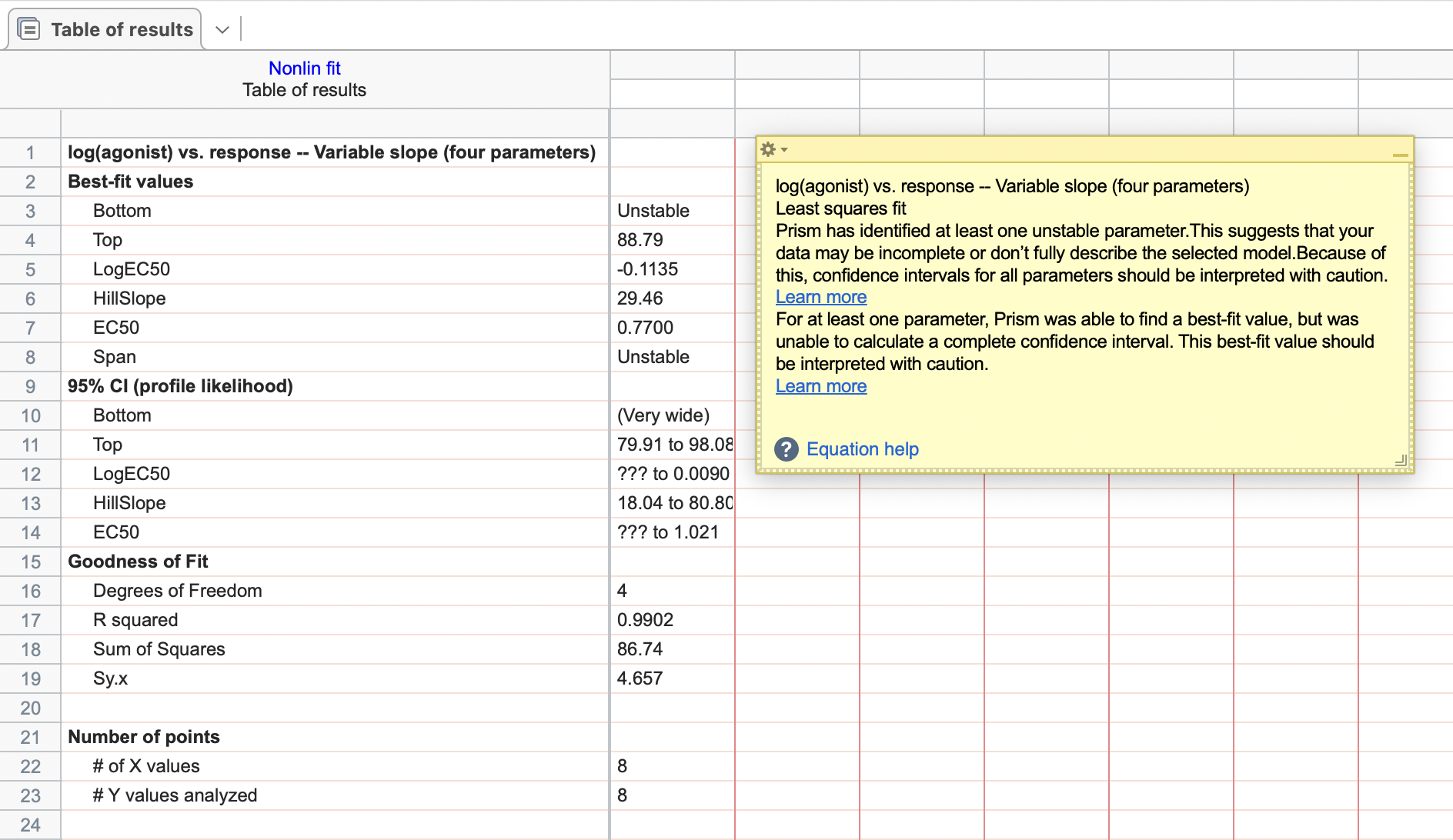
Prism10では、結果タブ内に示されるノートには、この結果にはおそらく意味がないと表示され、修正方法が示されます。Prism8.1以前では、フィットに”不明確/ambiguous”と記載して、値は信頼性が無いことを示すために、波形符号(~)を最適合値の前に付け、その信頼区間を表示しない仕様(信頼区間タブの不安定なパラメータと不明確なフィットの部分)でした。
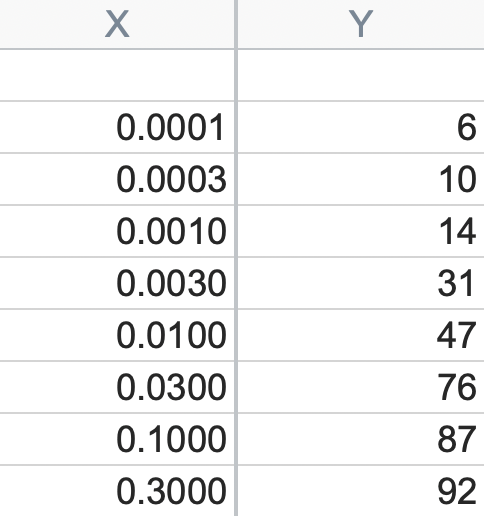
誤ったモデル(Xは実数なのに対数モデル)で行った解析
入力したデータ
結果:フローティングノートには失敗している原因と対処法が表示されています
Xを対数用量(Log10)に変換した後の解析
変換後のデータ
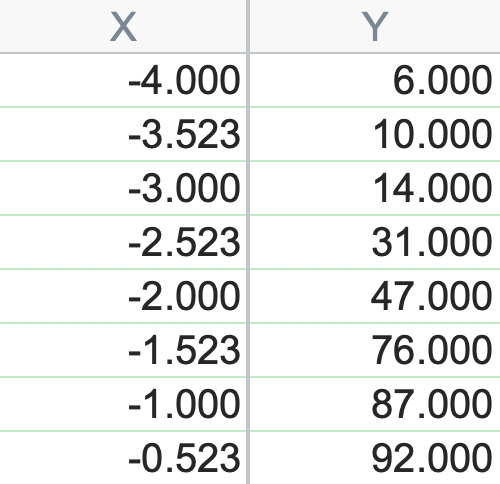
結果:フローティングノートの結果からエラーメッセージが消えました
* グラフの X軸のスケールを変更するには、Format Axes ダイアログから行います。Format Axes ダイアログを表示するには、ツールーバーの Change メニューにある 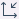 (Format Axes)ボタンをクリック、またはグラフの軸をダブルクリックします。
(Format Axes)ボタンをクリック、またはグラフの軸をダブルクリックします。
Scale は Linear がデフォルトで設定されていますが、このチュートリアルでは対数モデルと見た目を合わせるために Log10 を選択しています。
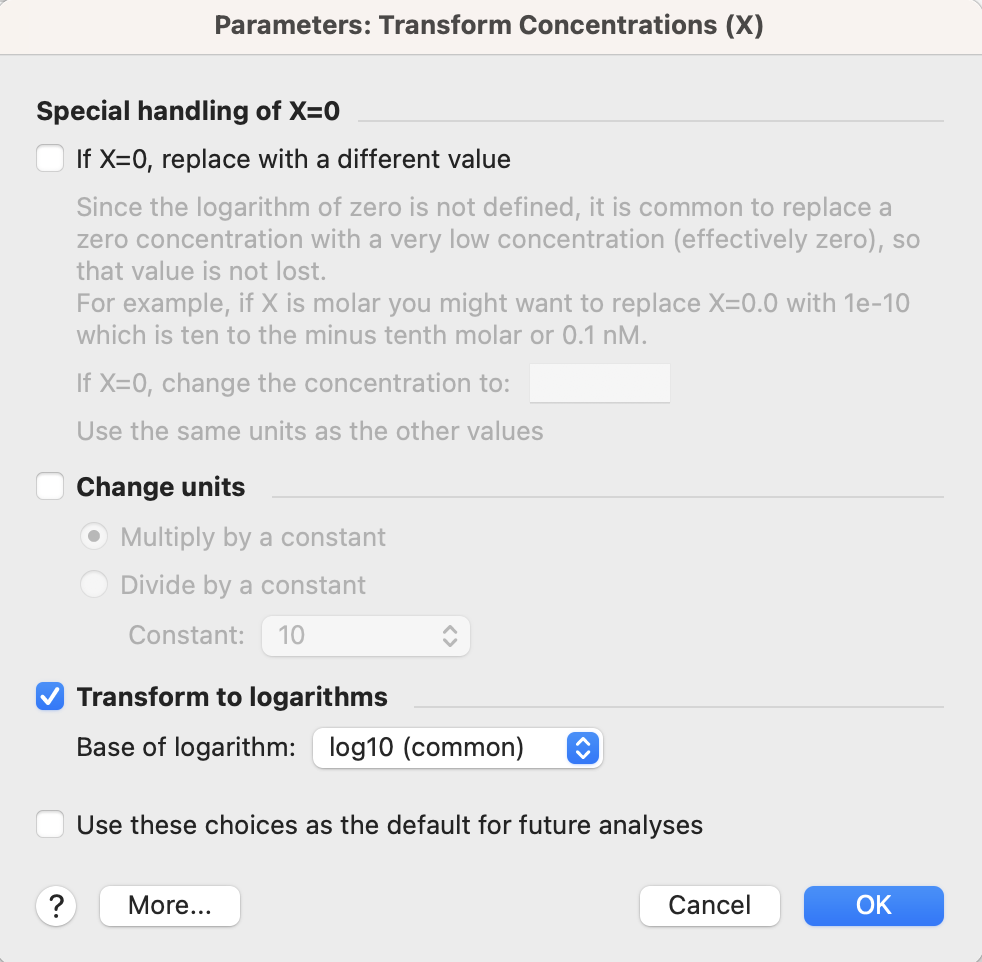
** X値を対数に変換する方法は以下の通りです。
1. ツールバーの Analyze ボタンをクリックし、Transform, Normalize... から Transform concentrations (X) を選択します。
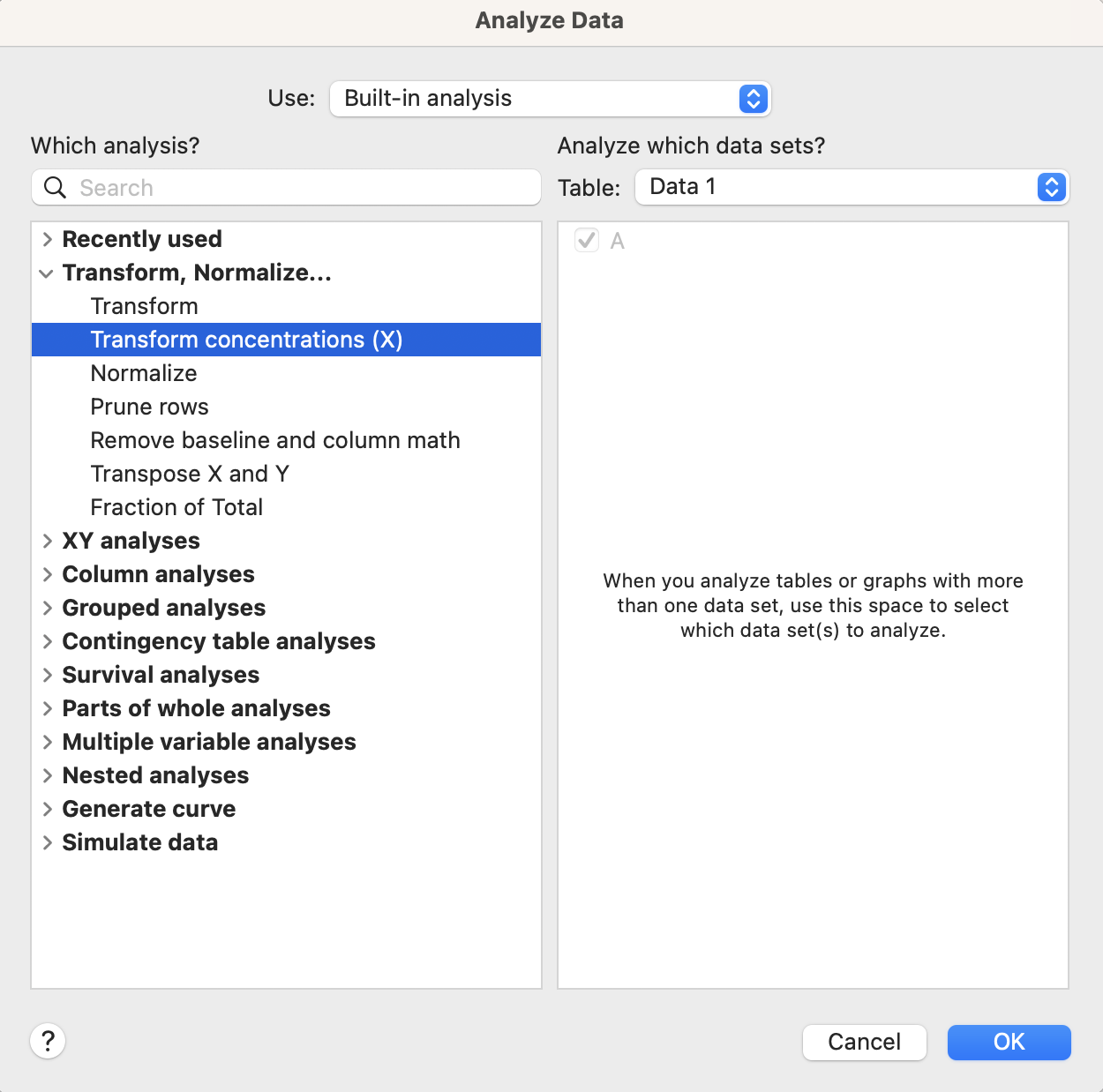
2. Parameters : Transform Concentrations (X) ダイアログで、Transfrom to logarithms にチェックを入れ、OK ボタンをクリックします。
「非線形回帰チュートリアル」オリジナル版では、『Prismでの非線形回帰の結果の説明』『実務でよく起こり得る問題への対処のヒント』が掲載されています。