2025年8月22日
詳細はGraphPad社 サイトでご確認ください。
Magicでタイトルの制御が改善されました
Magic を使用することで、グラフのフォーマットをより詳細にコントロールできるようになり、グラフ、X 軸、および Y 軸のタイトルそれぞれに対して個別のコントロール*が用意されます。
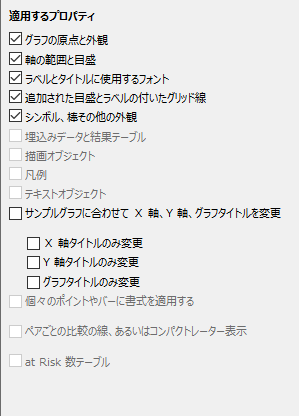
- 別個のコントロール: グラフ、X軸タイトル、Y軸タイトルを、選択的に修正できます。
- 簡略化されたワークフロー: 全ての3つのタイトルをクリック一つで切り換えます。
- カスタマイズ: 他のグラフエレメントに影響を及ぼすことなく、簡単にタイトルに変更を適用できます。
* ネームドユーザーPrismライセンスが必要です(シリアル番号に基づくPrismライセンスで利用できませんん)
「抽出と再構成」[Extract and rearrange] のコントロールの改善
新しいオプションにより、データ抽出と再構成についてより正確な制御が可能になりました。
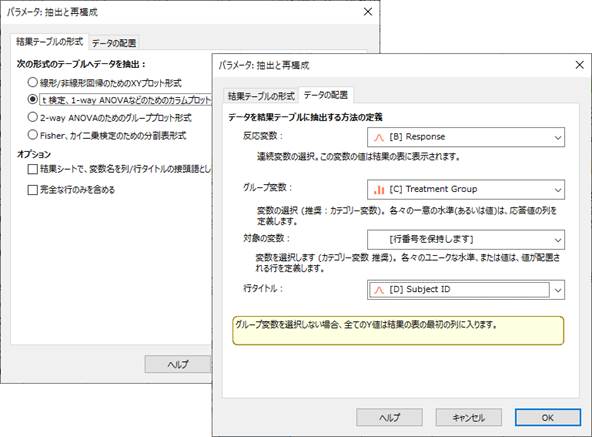
- 完全な行だけ: ブランク、あるいは空の行を除外し、完全な行だけを出力するするための新しいオプション。
- 対象変数/Subject Variable のサポート: データを繰り返し測定分析のための列形式に抽出するとき、対象 (行) の変数を指定します。
- カスタム行タイトル: 指定された変数あるいは行タイトルの値を抽出された結果に引き継ぎます。
- 適切な警告: 複数の値が同じセルに割り当てられているときに、データ消失を防ぐためにフローティングメモによってユーザーにアラートを出します。
重回帰についてのより直観的な [信頼区間/Confidence Interval] オプション
簡素化された信頼区間のコントロールにより、線形重回帰分析、多重ロジスティック回帰分析、およびコックス比例ハザードモデルがより利用しやすく、理解しやすくなりました
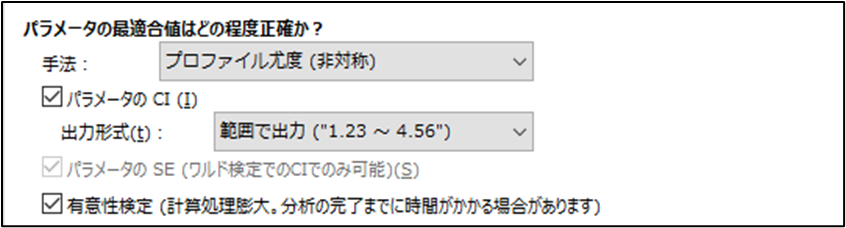
- 明確な手法の選択: 開始時に、プロファイル尤度または ワルド/Wald 信頼区間を選択します。
- カスタマイズ可能な出力: 上限/下限、標準誤差、P 値を含む出力する結果を指定します。
- 能率的なインターフェース: 新しい配置により、信頼区間の設定が分かりやすく、かつ設定しやすくなりました。
K-means クラスタリングでクラスター数を自動選択
データセットに対し最適なクラスター数を自動的に決定する、新しいコンセンサス メトリック機能** の使用により、K-means クラスタリングの推測作業が不要になりました。
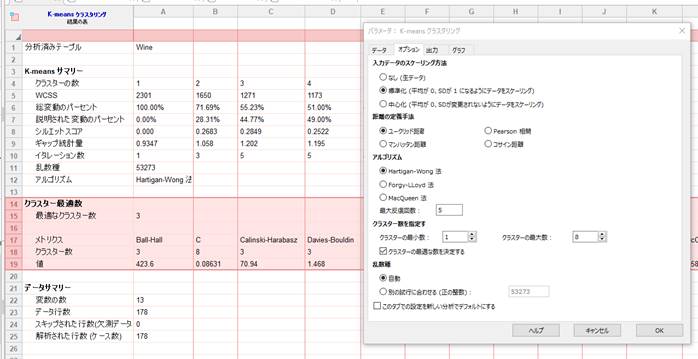
- 複数の手法によるアプローチ: 異なるメトリックに基づいてクラスターの最適な数を決定するために17の手法が使用されます。
- コンセンサスに基づく決定: 17 の検定全体で最も頻繁に推奨されるクラスターの数を選択するコンセンサス手法が使用されます。
- 精度: 範囲が広すぎたり断片化されすぎたりしたパターンを回避し、より有意義なクラスタリング結果が導き出す手助けとなります。
クラスター数の選択での注意
データに対し、正しいクラスター数を見つけることは困難です。 クラスターの数が少なすぎると需要な相違を見落とすことになり、クラスターの数が多すぎると不適切なグループ化をもたらします。
Prism 10.6 は、17 の異なる手法からメトリクスを計算することでこの問題に取り組み、各々の手法は、特定のデータのクラスタリングを最適化する方法を決定するための独自の基準を備えています。
これらの17の手法から最も多くの”投票”を獲得したクラスターの数が、Prismが推奨するもので、より信頼性が高く頑健な結果を提供します。 このアプローチは多くの場合コンセンサス手法と呼ばれ、最終的な答えは複数の独立した測定結果の合意によって決定されます。
**この機能が GraphPad Prism for Enterprise でのみ利用可能である点に注意してください。
* ネームドユーザーPrismライセンスが必要です(シリアル番号に基づくPrismライセンスでは利用できませんん)
** Prism Enterprise license ライセンスが必要です
*** 関連するPrism Cloud Workspace が利用可能な Prism サブスクリプションが必要です
















